



Technical Optimisation for Articles
Success in Top Stories is about more than just writing great headlines. The HTML with which you deliver your articles to search engines is a large part of the equation too.

If you’ve been reading my newsletters so far, you won’t have escaped the fact that getting your news content crawled and indexed quickly by Google is crucial to SEO success.
In most cases, the initial window of Top Stories visibility is less than 48 hours, and Google has a strong preference for ‘first publishers’ when it comes to showing news articles on breaking stories and latest developments. Hence the importance of rapid Google indexing of newly published articles.
In this newsletter, I’ll be discussing some ways you can enable effortless indexing of your content and remove potential stumbling blocks for Google’s indexing systems.
There are many different aspects that come into play, and here I’ll focus purely on the articles themselves - specifically, the article’s HTML source code.
Multitier Indexing
The fact that Google has a multi-layered indexing system has not been a secret for a while now.
Several years ago Google openly admitted to using at least two stages of indexing. The first stage is when Google parses the raw HTML of the page, and then there’s a second rendering stage where the page is loaded in a headless Chrome browser and relevant client-side code is executed.
This is how Google visualises the process:

The rendering aspect of indexing is not instantaneous. From Google’s documentation on JavaScript & SEO (emphasis added):
“Googlebot queues all pages for rendering, unless a robots meta tag or header tells Googlebot not to index the page. The page may stay on this queue for a few seconds, but it can take longer than that. Once Googlebot's resources allow, a headless Chromium renders the page and executes the JavaScript.”
This, plus the additional statement that Google “also uses the rendered HTML to index the page” has led many developers to assume that relying on client-side JavaScript is perfectly fine for SEO.
Unfortunately, this is most definitely not the case.
While the intricacies of JavaScript and SEO are beyond the remit of this newsletter, let’s suffice to say that using client-side JS to load page content is an exceptionally bad idea. Even Google admit that using server-side rendering is preferable:
“Keep in mind that server-side or pre-rendering is still a great idea because it makes your website faster for users and crawlers, and not all bots can run JavaScript.”
In the context of news, using client-side JavaScript for content is actively discouraged. In their Technical Requirements documentation for news publishers, Google explicitly state the following (emphasis added):
“Your articles’ pages should use HTML format and the body text isn't embedded in JavaScript.”
There’s a very good reason for that. While Google hopes to be able to render all the pages it chooses to index, the delay that the rendering phase introduces into the indexing process is unpredictable.
Sometimes Google can render pages within seconds of crawling it, and sometimes the delay is minutes or even hours. Google can’t guarantee it’ll have the resources available to render news websites’ articles immediately. If Google were to wait for that rendering to be completed, indexing delays could occur. The fast-paced nature of news makes that an unacceptable risk.
So when Google indexes news articles for use in Top Stories and Google News, there is no rendering phase. Google indexes an article’s raw HTML and does its best to extract the article’s headline and contents. Client-side JavaScript is not executed.
Google relies purely on the HTML source for indexing an article’s contents for Google News. And while Google’s parsing of HTML is pretty damn good, it’s not perfect. This has repercussions for how publishers should format their articles’ HTML.
SEO is Probabilistic
Before I dig into the specifics, I want to discuss how we should think about SEO.
In the early days of the web, getting webpages to rank in search engines was a pretty deterministic affair. If you followed a specific formula containing several ‘ingredients’ (keywords, links, anchor texts, etc.) then your webpages would inevitably surface on the first page of search results.
The quality and quantity of ingredients could vary and the resulting rankings would fluctuate accordingly, but it was a fairly causal process.
Nowadays, SEO is rather different. The number of ingredients has grown exponentially, and search engines have become vastly more complex. Instead of thinking about SEO as a deterministic process (do A, and B happens), we need to see SEO as a probabilistic affair (do A, and there’s a chance that B will happen).
The following tips about optimising article HTML is all about improving probabilities. Specifically, serving optimal HTML to Googlebot reduces the probability of something going wrong with Google’s indexing of your article.
So what follows isn’t necessarily intended to help you boost your Top Stories rankings. Rather, these best practices are helpful to minimise the chances of your article not getting indexed.
Serving suboptimal HTML to Google doesn’t mean an article definitely won’t get indexed. In most cases, Google can handle poorly optimised HTML just fine and an article embedded in cluttered HTML will be indexed and can rank.
However, sometimes poor HTML causes a hiccup, and Google won’t index the article. Optimising your article HTML reduces the chances of that happening.
Optimising the <HEAD>
Let’s start with where HTML starts: the <head> of the page. The <head> section of an article’s HTML contains several crucial elements that we definitely want Google to parse.
These include the <title>, <meta name="description">, <link rel="canonical">, <link rel="amphtml">, <meta name="robots"> instructions, and various <link rel="alternate"> tags containing references to hreflang and/or mobile alternative URLs. Additionally, the <head> is where Open Graph meta tags reside that Google often seems to rely on as well.

Generally it’s recommended to also put the article’s relevant structured data snippet in the <head> as well. Theoretically you could put it anywhere in the HTML source, but practically it’s safest to put it in the <head> to ensure Google reads and processes it.
Why is that? Well, as we’ve learned through trial and error (lots of error), Google doesn’t always parse the entire <head> correctly.
I’ve personally encountered several scenarios where Google failed to recognise crucial meta tags such as hreflang, canonicals, and structured data snippets. In all of these cases, prioritising these elements in the <head> resulted in Google starting to properly parse these elements.
Prioritising these elements means putting them at the start of the <head> before any CSS and JavaScript snippets. We’ve repeatedly seen that this results in a reduced error rate and a greater chance of Google flawlessly parsing these meta tags and structured data snippets.
What would cause Google to not properly recognise all <head> elements? I could dedicate an entire newsletter to explain that, but this article from Oliver Mason already does a good job.
Summarised, sometimes code in the <head>, such as HTML embedded in <noscript> tags, can cause Google to believe the <head> has ended and the <body> has begun. Any meta tags present below such <head>-breaking code will duly be ignored by Google, as the search engine (correctly) doesn’t obey any meta tags it believes resides in the HTML page’s <body>.
Properly ordering the meta tags in an article’s <head> reduces the chances of any such hiccups and ensures Google will almost always properly recognise and process your important meta tags and structured data snippets.
Optimising Article HTML
A long time ago (in SEO terms), news publishers had access to a special crawl errors report in Webmaster Tools/Search Console. These reports showed errors Google encountered when indexing articles on publishers that were approved for Google News inclusion.
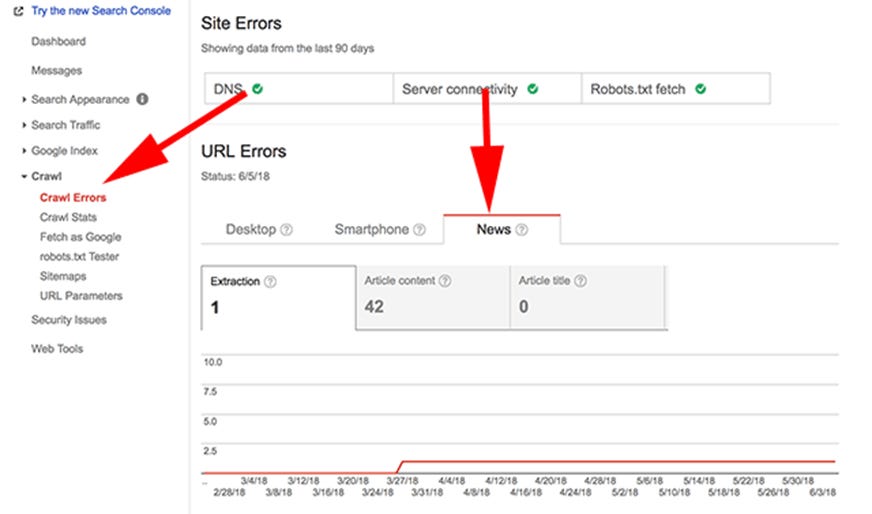
These special reports were discontinued in 2018, which is unfortunate as they provided a wealth of information to publishers that could be used to optimise article HTML.
Some of the errors reported in there were issues like ‘article fragmented’ and ‘title not found’, and digging into these issues offered important clues about how Google parses an article’s HTML for indexing. Perhaps these were too useful, as they also highlighted some of Google’s weaknesses when it comes to processing HTML.
Debugging these errors was almost always a case of tidying up the article’s HTML and removing any potential points of confusion. This has resulted in a set of best practices that I still employ today, as I don’t believe Google’s parsing of HTML in that first stage of indexing has massively changed since then.
These best practices are:
The article headline should be the first <h1> heading
I strongly suspect Google looks for the first <h1> heading tag in an article’s HTML and starts parsing the article’s contents from that point onwards. As such, it’s important to make sure that the first <h1> heading in the HTML is indeed the article headline.
For general accessibility reasons, it’s recommended to only have one <h1> heading anyway, and this should be the webpage’s main headline.
Avoid encoded HTML in the article headline
I’ve seen many cases of Google failing to properly parse an article’s headline if it contained encoded strings for special characters - for example:

It’s safer to just use the actual characters or rely on UTF-8 escaped strings instead.
Limited the HTML above the opening <h1> headline
This is a bit speculative on my part, but I have a nagging suspicion Google limits the total size of the HTML it parses before it stops looking for an article’s headline.
I’ve encountered a case where the article HTML contained around 450 KB of CSS and scripts in the <head> and start of the <body> above the article <h1> headline, and it was very hit or miss for Google to index these articles. A good 1 in 5 articles were not properly indexed in Google News - these showed as ‘extraction failed’ errors in the news-specific crawl errors report.
When we reduced the HTML payload above the <h1> headline to around 100 KB, the failure rate was drastically reduced and Google had no issues indexing the articles for Google News and Top Stories.
Minimise interrupting HTML snippets in your article code
When Google finds an article’s opening <h1> headline, it parses the HTML below it to index the article’s contents.
Sometimes when the article’s HTML is interrupted by an unrelated snippet of code, such as a block of recommended articles, social sharing icons, or an image gallery, Google sees this as an indication the article content has ended. This can lead to partial indexing of the article’s contents.
In the old crawl errors report, these showed up as ‘article too short’ or ‘article fragmented’ errors.
I recommend trying to embed the article’s full contents in one uninterrupted block of HTML, from opening <h1> headline to the final paragraph.
Any elements you want to visually include within the article text on the rendered webpage in the browser should ideally sit below or (less ideally) above the article’s HTML in the source code. With proper CSS, you can insert these anywhere you want visually on the page - just make sure the HTML for these elements doesn’t break up the article contents.
Semantic HTML helps
In version 5 of HTML, additional semantic tags like <header>, <section>, <article>, and <footer> were introduced to signpost specific page elements in the HTML source.
While Google doesn’t need these semantic tags to be present, I do believe it helps with proper parsing of articles. At the very least these tags can inform Google which HTML segments it can ignore and where it should focus its attention to find an article’s actual contents.
TLDR: Clean Code Still Matters
Focusing on clean, semantic HTML may seem like an outdated perspective to take. It’s not something that many web developers pay much attention to. One glimpse at the HTML churned out by many platforms and frameworks makes a classic HTML coder (like yours truly) wince.
And to be fair, in most contexts clean HTML is pretty irrelevant. As long as the page can be properly rendered, the tidiness of the source code doesn’t matter.
For Google News, however, clean HTML is still rather important. Tidy code can make the difference between an article achieving good Top Stories visibility or failing to get indexed at all.
Like I said above, it’s about minimising the probability of an error occurring. Cleaning up your article HTML is a key element of shifting those probabilities in your favour.
Miscellanea
To wrap up this newsletter, here are some links to interesting content published in the last few weeks that you may find useful:
Google has published an expanded FAQ that addresses many more questions about core web vitals and the upcoming page experience update. There’s a lot of detail about AMP as well and how it relates to the page experience update, so you should definitely have a read.
LiveBlogPosting Schema: A Powerful Tool for Top Stories Success
How to Get a Red "LIVE" Badge in Google Using LiveBlogPosting Schema
Two articles hit the interwebz recently that focus on the LiveBlogPosting structured data markup and how it can enable a ‘Live’ badge in Top Stories. It’s something many publishers struggle with, and both articles offer interesting perspectives and hands-on recommendations.
This is a great guide from Lily Ray with tonnes of useful tips for publishers who want to grow their traffic in Google News and Google’s other news sources.
Tweaking the headlines of published articles is a common tactic many publishers experiment with. This write-up shows how the New York Times tests many different headlines in various contexts to try and get the best clickthrough rate.
Google has updated and expanded their documentation and resources on videos, with extra insights and tips to help publishers achieve good visibility for their video content.
Wrapping Up
Thanks for your patience, it’s been a bit of a slog to get this newsletter done. Turns out that the creative processes my brain uses to write this newsletter overlap with the processes for writing SEO audit reports. I’ve been doing a lot of those lately, leaving little cognitive resources for the newsletter.
This edition ticks off one of the topics that came out on top in my recent Twitter poll:

The syndicated content topic should be next, but as the core web vitals update is imminent I may prioritise that one.
As always, thanks for reading and subscribing - your support means a lot to me. If you enjoyed this newsletter, please do share it with anyone you feel might be interested.
Great newsletter and tips! Thank you.
Thanks for rich information, if google crawling my articles instantly, but also the articles not appearing in top stories, then what else can i check.